Qué es el ODBC?
Open Data Base Conectivity
O lo que es lo mismo, conectividad abierta de bases de datos. Si escribimos una aplicación para acceder a las tablas de una DB de Access, ¿qué ocurrirá si después queremos que la misma aplicación, y sin reescribir nada, utilice tablas de SQL Server u otra DB cualquiera? La respuesta es sencilla: no funcionará. Nuestra aplicación, diseñada para un motor concreto, no sabrá dialogar con el otro. Evidentemente, si todas las DB funcionaran igual, no tendríamos este problema.... aunque eso no es probable que ocurra nunca.Pero si hubiera un elemento que por un lado sea siempre igual, y por el otro sea capaz de dialogar con una DB concreta, solo tendríamos que ir cambiando este elemento, y nuestra aplicación siempre funcionaría sin importar lo que hay al otro lado... algo así como ir cambiando las boquillas de una manguera. A esas piezas intercambiables las llamaremos orígenes de datos de ODBC
Casi todas las DB actuales tienen un ODBC. Debido a que este elemento impone ciertas limitaciones, ya que no todo lo que la DB sabe hacer es compatible con la aplicación, como velocidad de proceso, tiempos de espera, máxima longitud de registro, número máximo de registros, versión de SQL, etc., está cayendo en desuso a cambio de otras técnicas de programación, pero aún le quedan muchos años de buen servicio.
Todo lo referido aquí funciona con Windows NT Server 4.0 con el Service Pack 4 o superior instalado (el último publicado es el 6). El Option Pack 4 para actualizar el IIS y las extensiones ASP. SQL Server 6.5 y Access 97. Por supuesto, también funciona con las versiones modernas de servidores como 2003 Server, y también XP PRO, que lleva un IIS 5.0 de serie. Igualmente es posible utilizar bases de datos de Access 2000 o 2003.
Esas otras técnicas de programación antes mencionadas, se utilizan ya en el nuevo Windows 2003, Office 2003 y SQL Server 2000, que además de ODBC pueden utilizar.... pero esa es otra historia.
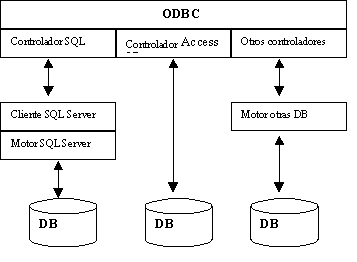
Esta es la idea: por un lado el ODBC provee de unas caracteríisticas siempre homogéneas, y por el otro permite distintos controladores que aseguran la conectividad de la aplicación con diferentes bases de datos.
Configurar orígenes de datos ODBC
Una aplicación de Conectividad abierta de bases de datos (ODBC) utiliza un origen de datos ODBC para conectarse a una instancia de Microsoft MicrosoftSQL Server. Un origen de datos ODBC es una definición almacenada que registra:
- El controlador ODBC que se va a utilizar para las conexiones que especifican el origen de datos.
- La información que utiliza el controlador ODBC para conectarse a un origen de datos.
- Opciones específicas del controlador que se van a utilizar para la conexión. Por ejemplo, un SQL Server origen de datos ODBC puede registrar las opciones de ISO que va a utilizar o si los controladores deben registrar estadísticas de rendimiento.